

As a search and analytics database, Rockset powers many personalization, anomaly detection, AI, and vector functions that want quick queries on real-time knowledge. Rockset maintains inverted indexes for knowledge, enabling it to effectively run search queries with out scanning over the entire knowledge. We additionally keep column shops that permit environment friendly analytic queries. Learn up on converged indexing to be taught extra about indexing in Rockset.
Inverted indexes are the quickest solution to discover the rows matching a selective question, however after the rows are recognized Rockset, must fetch the correlated values from different columns. This generally is a bottleneck. On this weblog put up we’ll speak about how we made this step a lot quicker, yielding a 4x speedup for patrons’ search-like queries.
Quick Search Efficiency for Fashionable Functions
For a lot of real-time functions, the power to execute search queries with millisecond latency at excessive queries per second (QPS) is crucial. For instance, try how Whatnot makes use of Rockset as their backend for real-time personalization.
This weblog presents how we improved the efficiency of search question CPU utilization and latency by analyzing search-related workloads and question patterns. We make the most of the truth that, for search-related workloads, the working set normally matches in reminiscence, and concentrate on enhancing the in-memory question efficiency.
Analyzing Search Question Efficiency in Rockset
Assume we’re constructing the backend for real-time product suggestions. To realize this, we have to retrieve a listing of merchandise, given a metropolis, that may be displayed on the web site in lowering order of their likelihood of being clicked. To realize this, we are able to execute the next instance question:
SELECT product_id, SUM(CAST(clicks as FLOAT)) / (SUM(CAST(impressions as FLOAT) + 1.0)) AS click_through_rate
FROM product_clicks p
WHERE metropolis = 'UNITED ST2'
GROUP BY product_id
ORDER BY click_through_rate DESC
Sure cities are of explicit curiosity. Assuming that the info for regularly accessed cities matches in reminiscence, the entire indexing knowledge is saved in RocksDB block cache, the inbuilt cache offered by RocksDB. RocksDB is our knowledge retailer for the entire indexes.
The product_clicks view incorporates 600 million paperwork. When town filter is utilized, round 2 million paperwork are emitted, which represents roughly 0.3 % of the full variety of paperwork. There are two attainable execution plans for the question.
- The fee-based optimizer (CBO) has the choice to make use of the column retailer to learn the required columns and filter out unneeded rows. The execution graph on the left of Determine 1 reveals that studying the required columns from the column retailer takes 5 seconds as a result of giant assortment measurement of 600 million paperwork.
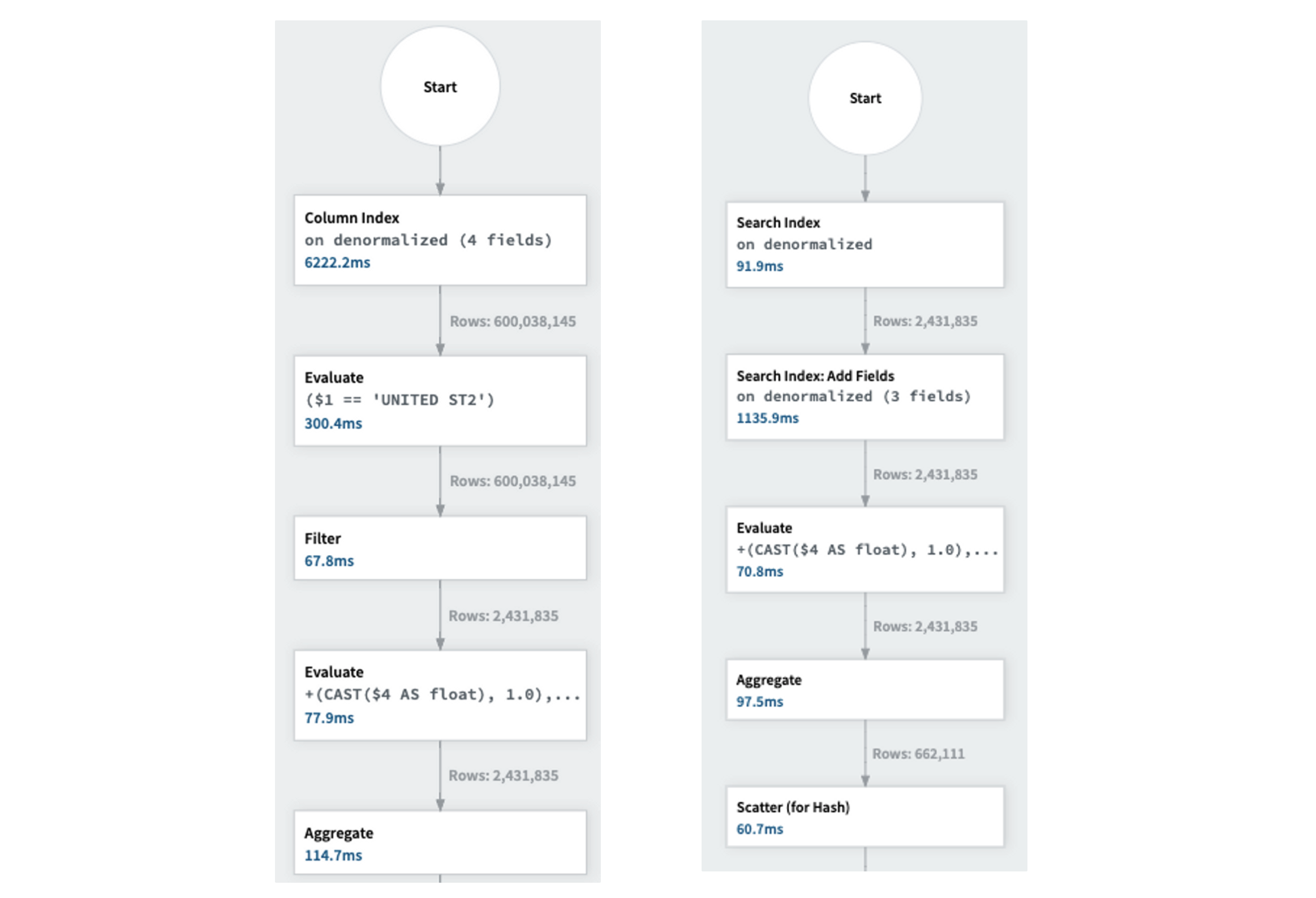
Determine 1: Question execution utilizing column retailer on the left. Question execution utilizing inverted/search index on the appropriate.
- To keep away from scanning your complete column, the CBO makes use of the inverted index. This permits the retrieval of solely the required 2M paperwork, adopted by fetching the required column values for these paperwork. The execution graph is on the appropriate of Determine 1.
The execution plan when utilizing the inverted index is extra environment friendly than that when utilizing the column retailer. The Price-Primarily based Optimizer (CBO) is subtle sufficient to pick the suitable execution plan mechanically.
What Is Taking Time?
Let’s look at the bottlenecks within the inverted index execution plan proven in Determine 1 and establish alternatives for optimization. The question executes primarily in three steps:
- Retrieve the doc identifiers from the inverted index.
- Acquire the doc values utilizing the identifiers from the Row Retailer. The row retailer is an index that’s a part of the converged index, mapping a doc identifier to the doc worth.
- Fetch the required columns from the doc values (i.e. product_id, clicks, impressions).
- The mixture of steps 2 and three is named the
Add Fields operation.
As proven within the execution graph, the Add Fields operation could be very CPU-intensive and takes a disproportionate period of time in question execution. It accounts for 1.1 seconds of the full CPU time of two seconds for the question.
Why Is This Taking Time?
Rockset makes use of RocksDB for all of the indexing methods talked about above. RocksDB makes use of an in-memory cache, known as the block cache, to retailer essentially the most just lately accessed blocks in reminiscence. When the working set matches in reminiscence, the blocks akin to the row retailer are additionally current in reminiscence. These blocks comprise a number of key-value pairs. Within the case of the row retailer, the pairs take the type of (doc identifier, doc worth). The Add Fields operation, is answerable for retrieving doc values given a set of doc identifiers.
Retrieving a doc worth from the block cache primarily based on its doc identifier is a CPU-intensive course of. It is because it includes a number of steps, primarily figuring out which block to search for. That is completed by way of a binary search on a RocksDB inside index or by performing a number of lookups with a multi-level RocksDB inside index.
We noticed that there’s room for optimization by introducing a complementary in-memory cache – a hash desk that immediately maps doc identifiers to doc values. We name this complementary cache the RowStoreCache.
RowStoreCache: Complementing the RocksDB Block Cache
The RowStoreCache is a Rockset-internal complementary cache to the RocksDB block cache for the row retailer.
- The RowStoreCache is an in-memory cache that makes use of MVCC and acts as a layer above the RocksDB block cache.
- The RowStoreCache shops the doc worth for a doc identifier the primary time the doc is accessed.
- The cache entry is marked for deletion when the corresponding doc receives an replace. Nonetheless, the entry is barely deleted when all earlier queries referencing it have completed executing. To find out when the cache entry will be eliminated, we use the sequence quantity assemble offered by RocksDB.
- The sequence quantity is a monotonically rising worth that increments on any replace to the database. Every question reads the info at a specified sequence quantity, which we discuss with as a snapshot of the database. We keep an in-memory knowledge construction of all of the snapshots at the moment in use. Once we decide {that a} snapshot is not in use as a result of all of the queries referencing it have been accomplished, we all know that the corresponding cache entries on the snapshot will be freed.
- We implement an LRU coverage on the RowStoreCache and use time-based insurance policies to find out when a cache entry ought to be moved on entry throughout the LRU record or faraway from it.
Design and implementation.
Determine 2 reveals the reminiscence structure of the leaf pod, which is the first execution unit for distributed question execution at Rockset.
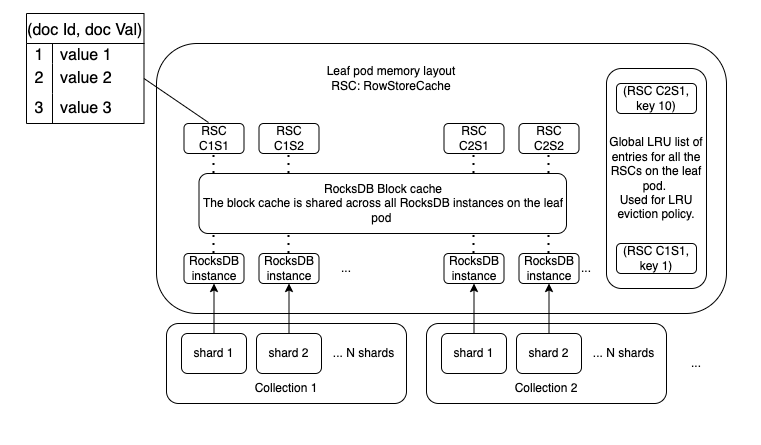
Determine 2: Leaf pod reminiscence structure with the RocksDB block cache and the RowStore caches. (RSC C1S1: RowStoreCache for assortment 1 shard 1.)*
In Rockset, every assortment is split into N shards. Every shard is related to a RocksDB occasion answerable for all of the paperwork and corresponding converged indexes inside that shard.
We applied the RowStoreCache to have a one-to-one correspondence with every shard and a world LRU record to implement LRU insurance policies on the leaf pod.
Every entry within the RowStoreCache incorporates the doc identifier, the doc worth, the RocksDB sequence quantity at which the worth was learn, the newest RocksDB sequence quantity at which the entry has seen an replace, and a mutex to protect entry to the entry by a number of threads concurrently. To help concurrent operations on the cache, we use folly::ConcurrentHashMapSIMD.
Operations on the RowStoreCache
-
RowStoreCache::Get(RowStoreCache, documentIdentifier, rocksDBSequenceNumber)
This operation is easy. We test if the documentIdentifier is current within the RowStoreCache.
- Whether it is current and the doc has not acquired any updates between the sequence quantity it was learn and the present sequence quantity it’s queried at, we return the corresponding worth. The entry can also be moved to the highest of the worldwide LRU record of entries in order that the entry is evicted final.
- If it isn’t current, we fetch the worth akin to the doc identifier from the RocksDB occasion and set it within the RowStoreCache.
-
RowStoreCache::Set(RowStoreCache, documentIdentifier, documentValue, rocksDBSequenceNumber)
- If the get operation didn’t discover the documentIdentifier within the cache, we attempt to set the worth within the cache. Since a number of threads can attempt to insert the worth akin to a documentIdentifier concurrently, we have to make sure that we solely insert the worth as soon as.
- If the worth is already current within the cache, we set the brand new worth provided that the entry will not be marked to be deleted and the entry corresponds to a later sequence quantity than the one already current within the cache.
-
EnsureLruLimits
- When an entry is added to the worldwide LRU record of entries and we have to reclaim reminiscence, we establish the least just lately accessed entry and its corresponding RowStoreCache.
- We then take away the entry from the corresponding RowStoreCache and unlink it from the worldwide LRU record if the details about updates within the entry to the doc will not be related.
Efficiency Enhancements with the RowStoreCache
Latency Enhancements
Enabling the RowStoreCache within the instance question resulted in a 3x enchancment in question latency, decreasing it from 2 seconds to 650 milliseconds.
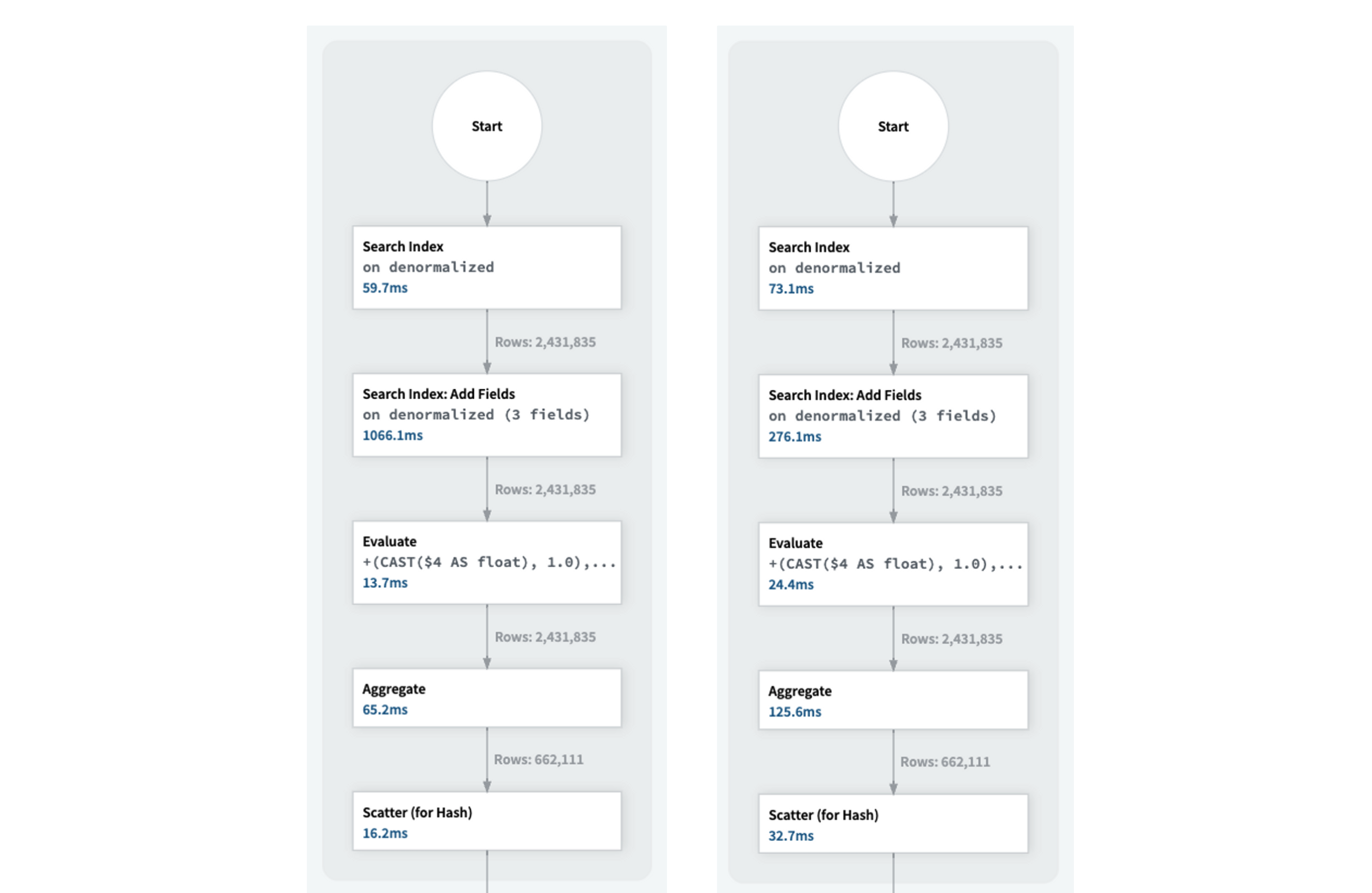
Determine 3: Question execution with out the RowStoreCache on the left. Question execution with the RowStoreCache on the appropriate.
Determine 3 reveals that the “Add fields” operation took solely 276 milliseconds with the RowStoreCache, in comparison with 1 second with out it.
QPS Enhancements
Executing the instance question with completely different filters for town at excessive QPS confirmed an enchancment in QPS from 2 queries per second to 7 queries per second, in keeping with the lower in latency per question.
This represents a 3x enchancment in QPS for the instance question.
The capability of the RowStoreCache will be tuned primarily based on the workload for optimum efficiency.
Now we have noticed related efficiency enhancements of as much as 4x in question latency and QPS for numerous search queries from a number of clients utilizing the RowStoreCache.
Conclusion
We’re consistently striving to enhance our caching technique to attain the very best question efficiency. The RowStoreCache is a brand new addition to our caching stack, and outcomes have proven it to be efficient at enhancing search question efficiency, on each latency and QPS metrics.
Weblog authors: Nithin Venkatesh and Nathan Bronson, software program engineers at Rockset.

{kind=link}